Streaming logs using RabbitMQ
More data stacks are shifting towards microservices and communication between them are essential as it sometimes need to communicate to more than one service. Message brokers play a critical part in this architecture by allowing services to communicate by routing messages and storing them. In this post we will be creating a real-time log viewer that consolidates errors across several apps and a python app to process error logs.

Introduction
In a previous post we created a streaming log viewer using FastAPI that read the last few lines a log file. While this is a good application, issues may arise with having multiples of these running in terms of file read/write access. We may also miss warning or error messages as no filtering was applied.
To overcome these issues, we are going to use RabbitMQ as a message broker as it is lightweight, easy to deploy and supports multiple messaging protocols. The working concept is illustrated in the below image. You have a producer of a message which goes into an exchange. From the exchange, you define one or more message queues that a consumer will connect to. The type of exchanges will vary according to the application and protocol used.
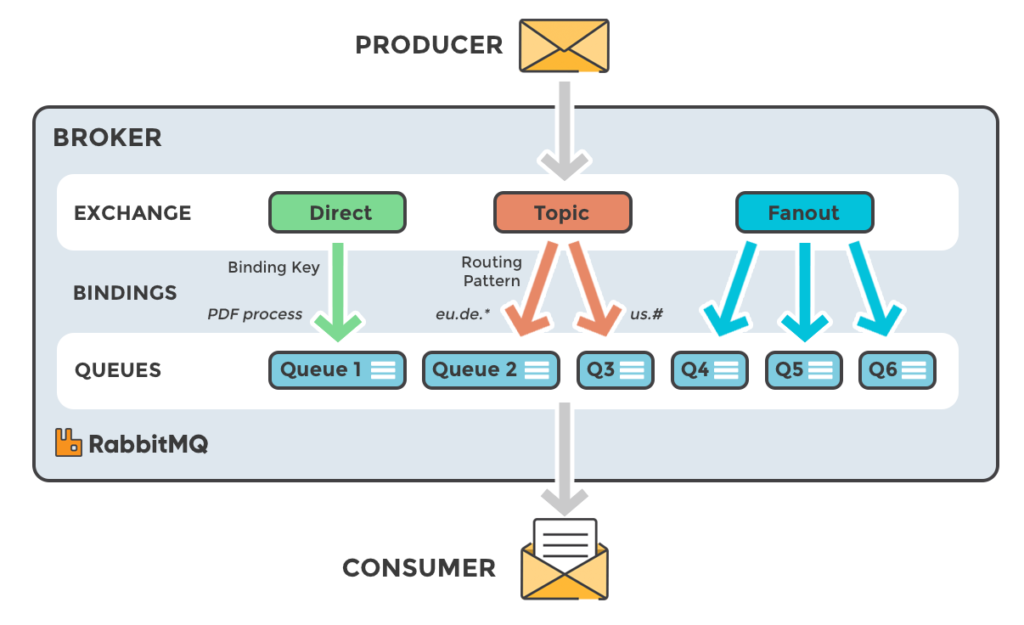
In this case, we are going to have three log producers, which are our python apps. They will send log data to the topic exchange. For our consumers, the first one will be a simple HTML page that connects via websockets, directly to the exchange. The second consumer will be a python app to process error logs from the message queues.
Setting up RabbitMQ
The first step is to install Erlang, which is a prerequisite, and then RabbitMQ. Once installed, we open the RabbitMQ command line and enable the management web interface and the MQTT over websockets plug-ins:
# web management plugin
rabbitmq-plugins enable rabbitmq_management
# mqtt over websockets
rabbitmq-plugins enable rabbitmq_web_mqttThe management interface will be available at http://localhost:15672/ with default username and password guest. All MQTT messages go via the amq.topic exchange by default but can be configured in the config file.
We will use the default exchange and next create the three queues we will need. For app1 and app2 we only create queues for ERROR messages while for app3 we will queue all log messages.

Now that we have the queues, we need to bind them to the exchange and add the Routing key. The routing key would be the topic from the producers and the python package we will be using will create topics for us using the logger’s name and then the logging level, e.g. app1/ERROR.
Important to note that topics normally contain / which would need to be converted to . in the Routing key. Thus, a topic defined as app3/ERROR would have a routing key of app3.ERROR. Also worth noting, these are case-sensitive.

Creating the log producers
For the producers, we will setup three python apps that log messages. We will be using a python package called python_logging_rabbitmq that can be found here. We setup a logging handler specifically for RabbitMQ and specify the exchange explicitly as amq.topic as the default defined in the python package is logs.
The log handler will produce JSON messages that are sent to the exchange. When defining the handler, we can also add additional fields to the message, in this case {"source": f"{APP_NAME}-producer", "env": "development"}. A typical JSON message will look like this:
{
"name": "app1",
"msg": "*** this is a log message from 'app1'.",
"args": null,
"levelname": "ERROR",
"levelno": 40,
"pathname": ".\\producer1.py",
"filename": "producer1.py",
"module": "producer1",
"exc_info": null,
"exc_text": null,
"stack_info": null,
"lineno": 38,
"funcName": "<module>",
"created": 1668934072.0913537,
"msecs": 91.3536548614502,
"relativeCreated": 310199.5060443878,
"thread": 17616,
"threadName": "MainThread",
"processName": "MainProcess",
"process": 32972,
"source": "app1-producer",
"env": "development",
"host": "instinct"
}
Once we run all three producers, we can see the messages coming through and messages being added to the queues. In producer three, we can see more messages are being logged as we are logging DEBUG, INFO, WARNING and ERROR messages. Clicking on the queues gives more details and statistics.

Creating the log consumers
For the consumer, we create a simple HTML page and style it with Tailwind CSS. We use JavaScript to initiate the websockets connection and process the log messages.
In RabbitMQ, we see a new queue from our web browser, prefixed with mqtt-subscription.


With this connection, we are consuming messages directly from the exchange amq.topic. We are not consuming messages from the queues; however, this can be enabled in the newer versions if needed. We can see on the messages still increasing in number in the queues. Once our simulated producers stop running, the state will turn to idle, but the messages will remain in the queues.
Reading messages from the queues is a destructive operation, meaning once it is read, it is removed from the queue. This is something we may not want for our ERROR messages. We want to log the errors in a central location for all our apps. Here we create our second consumer that reads messages from the queues using the pika library. The code comes from one of the RabbitMQ tutorials.
Below we see the output of the second consumer, processing messages from the queue and just printing them for illustration. In practise, these will typically be logged to a file or database for reporting. We can go one step further and use these logs to trigger restart of services, creating tickets or launching backfill processes.

app1-error queue messages with consumer2.py.As we processed all the previous messages in the app1-error queue, the queue length is zero as we process new messages as they come in with the second consumer.

app1-error from the past and continuing the process new messages as they arrive.Conclusion
We leveled up our logging game by consolidating our ERROR messages across three apps into central message queues, using RabbitMQ. Then we created a web consumer to monitor our application in real-time in an HTML page. Our second consumer processed the messages in the queues from the past to the present.
While this case shows the application in logging, the application of message queues reaches far beyond this. For example, in IoT data streaming where internet connections are not stable it provides local redundancy and ensures data is not lost. It can also be used for event streaming, like changing of process states which may require human intervention.
Full code available on GitHub.



0 Comments